Transformer Architecture: The Engine Behind Every LLM
Written by - Millan Kaul
Attention architecture explains the engine behind LLMs: how transformer layers turn tokens into intelligent output.
WHY?
- Default model architecture: transformers are the basis for modern LLMs, so understanding their flow helps you reason about behavior, limits, and failure modes.
- Debugging scope: transformers help you tell whether a problem is an architecture limit (context window, positional encoding) or a prompt/data issue.
WHAT?
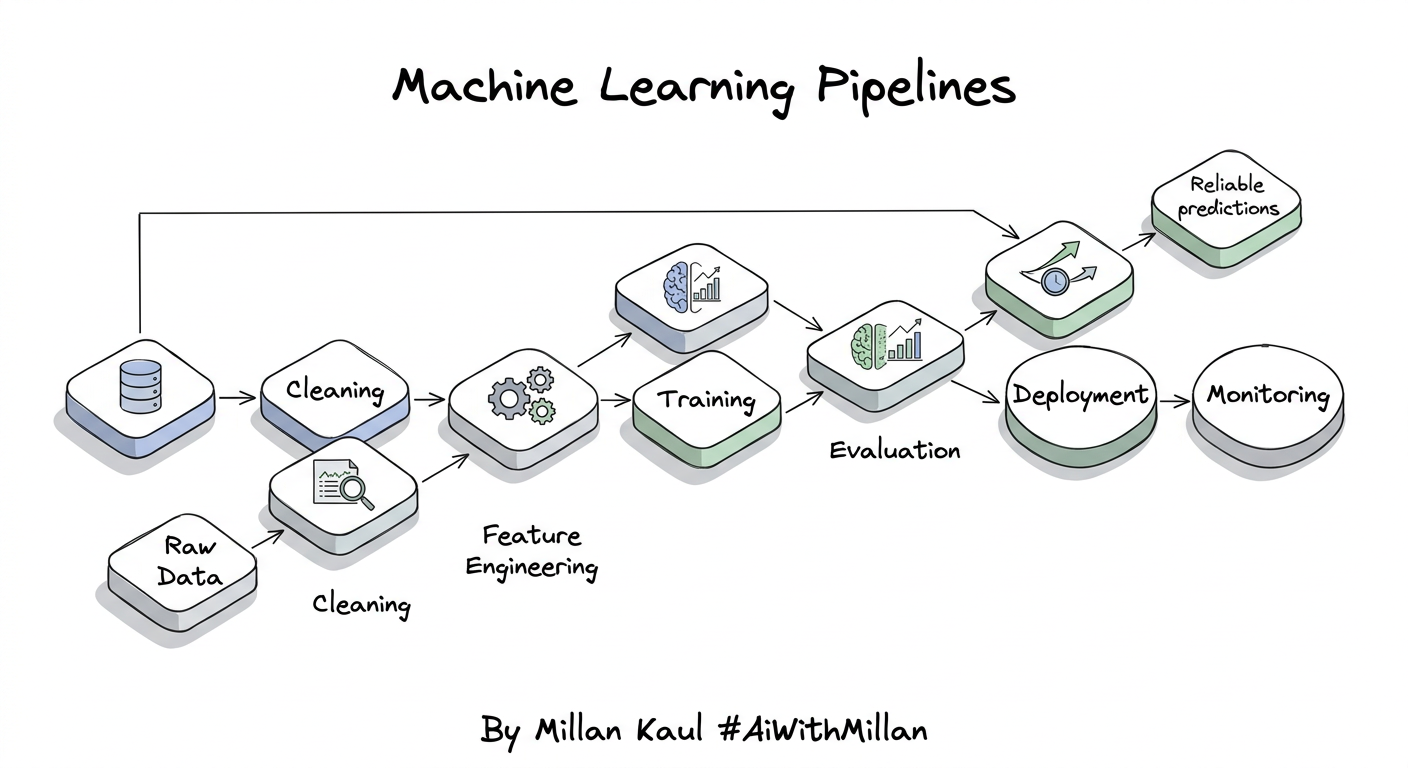
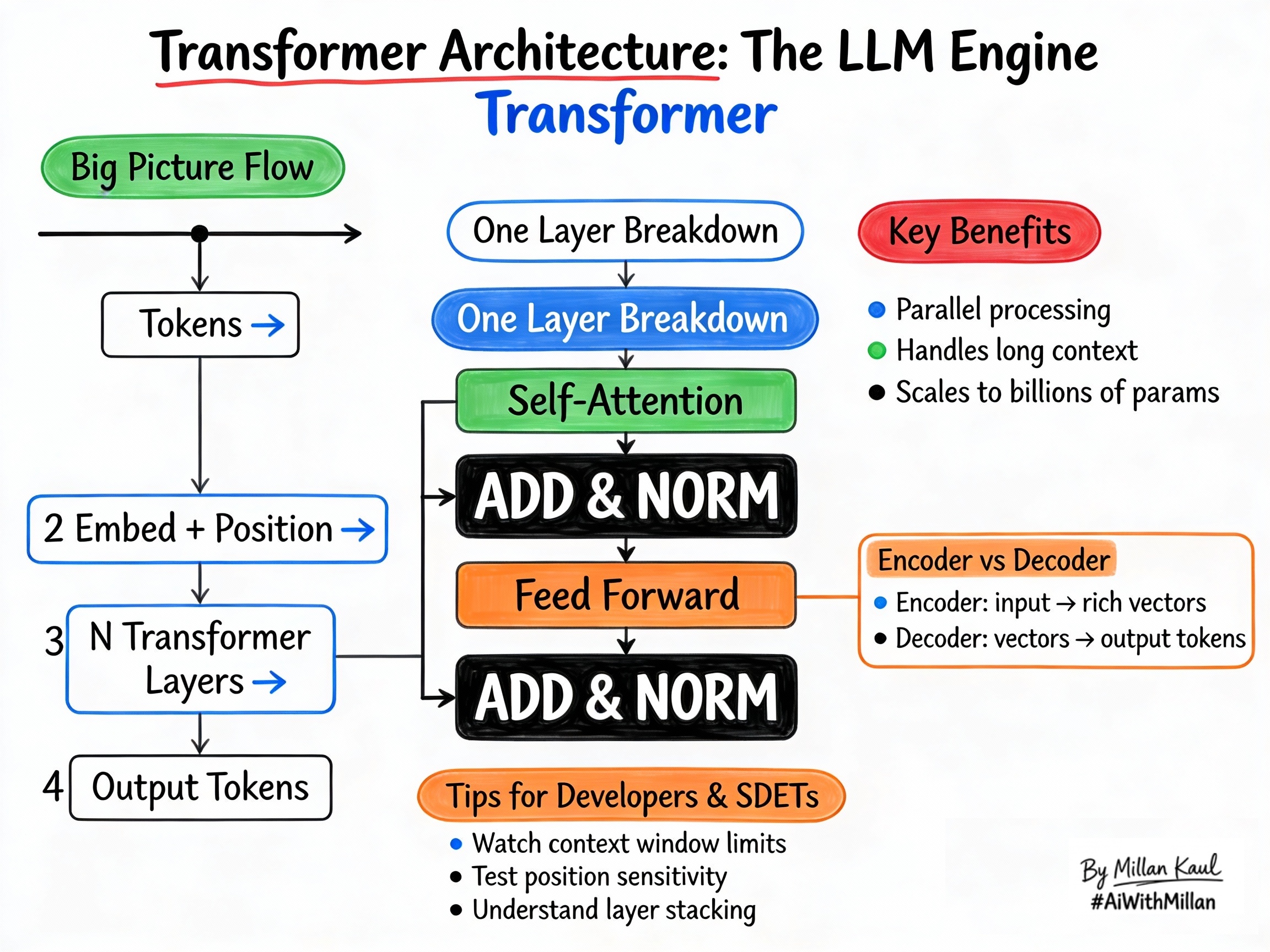
- A transformer is a neural network architecture for sequence processing. It uses stacked layers with self-attention and feed-forward networks.
- Encoders build rich representations from inputs. Decoders generate output tokens one by one.
- Each transformer layer contains: self-attention (to focus on relevant tokens), add & norm (for stability), and feed-forward (for nonlinear processing).
Concrete examples:
- Encoder-only (BERT): input → rich context vectors, good for classification and search.
- Decoder-only (GPT): prompt → next token → repeat, good for generation and chat.
- Encoder-decoder (T5): input → output, good for translation and summarization.
Quick rule of thumb: transformers are built from repeated attention + feed-forward blocks.
WHEN?
When transformers are central
- Any time you’re working with LLMs for generation, summarization, or translation tasks, since they’re all transformer-based decoders.
- When debugging long-sequence behavior (context window limits, forgetting early details), since attention and positional encoding are the key mechanisms.
If you are a Leader consider: When evaluating models for production: transformer variants differ in size, speed, context length, and capabilities, so architecture matters for selection.
When you can stay high-level
- For prompt engineering and testing, you only need the conceptual flow; the layer details are handled by the model provider.
- For leadership: Transformers are now “table stakes”; focus more on practical capabilities (context window, speed, cost) than the architecture itself unless building from scratch.
WHERE?
Think about where transformers live in the stack.
- Inside every LLM call: your prompt tokens go through the transformer layers before generating a response.
- In model cards and docs: specs mention “layers,” “heads,” “context length,” all transformer parameters you can use to pick the right model for the job.
From a Leadership angle: In architecture decisions: hosted vs local, encoder-only vs decoder-only vs encoder-decoder for different tasks.
Concrete examples:
- Prompt → Response Pipeline: tokenizer → embeddings → transformer layers → logit probabilities → sampled token → repeat.
- Context Window: positional encodings limit how far back the model can “remember” reliably.
- Scaling: more layers/heads/parameters = better but slower/more expensive.
HOW?
1. Conceptual steps (one layer)
- Input tokens → Embeddings + Position
- Convert tokens to vectors, add position info so the model knows order (since attention doesn’t inherently know sequence).
- Self-Attention
- Each token attends to all tokens (using QKV) to build a richer representation that considers context.
- Add & Norm
- Add (residual): adds input back to attention output for gradient flow. Norm (layer norm): stabilizes activations.
- Feed-Forward Network
- Applies non-linear transformations to each token independently, letting the model learn complex patterns.
- Repeat across many layers
- 12–96+ layers stack to capture increasingly abstract relationships.
2. Examples
- Single Layer: input “The cat sat” → attention links cat→sat → feed-forward adds pattern recognition → richer vectors.
- Multi-Layer: early layers catch syntax (“subject verb”), later layers catch semantics (“animal action location”).
- Decoder-Only (GPT style): generates tokens one by one, attending to all previous tokens + prompt.
3. Testing mindset
- Test position sensitivity: does reordering critical instructions change behavior?
- Test long context: does the model still respect early constraints after 10k+ tokens?
- From a Leadership view: Use model specs (layers, heads, context length) to match capabilities to requirements.
Reference
- The Illustrated Transformer – Jay Alammar jalammar.github.io
- MachineLearningMastery – “The Transformer Attention Mechanism” machinelearningmastery.com
- GeeksforGeeks – “Transformer Attention Mechanism in NLP” geeksforgeeks.org