Machine Learning Pipelines: The Backbone of Reliable AI Systems
Written by - Millan Kaul
Machine learning pipelines turn raw, messy data into deployable models through a repeatable set of automated steps. In practice, the pipeline is what makes ML usable in the real world, because it connects data ingestion, preprocessing, training, evaluation, deployment, and monitoring into one reliable flow.
Opinion: Without a pipeline, ML is mostly experimentation. With one, it becomes engineering.
Core Pipeline Stages
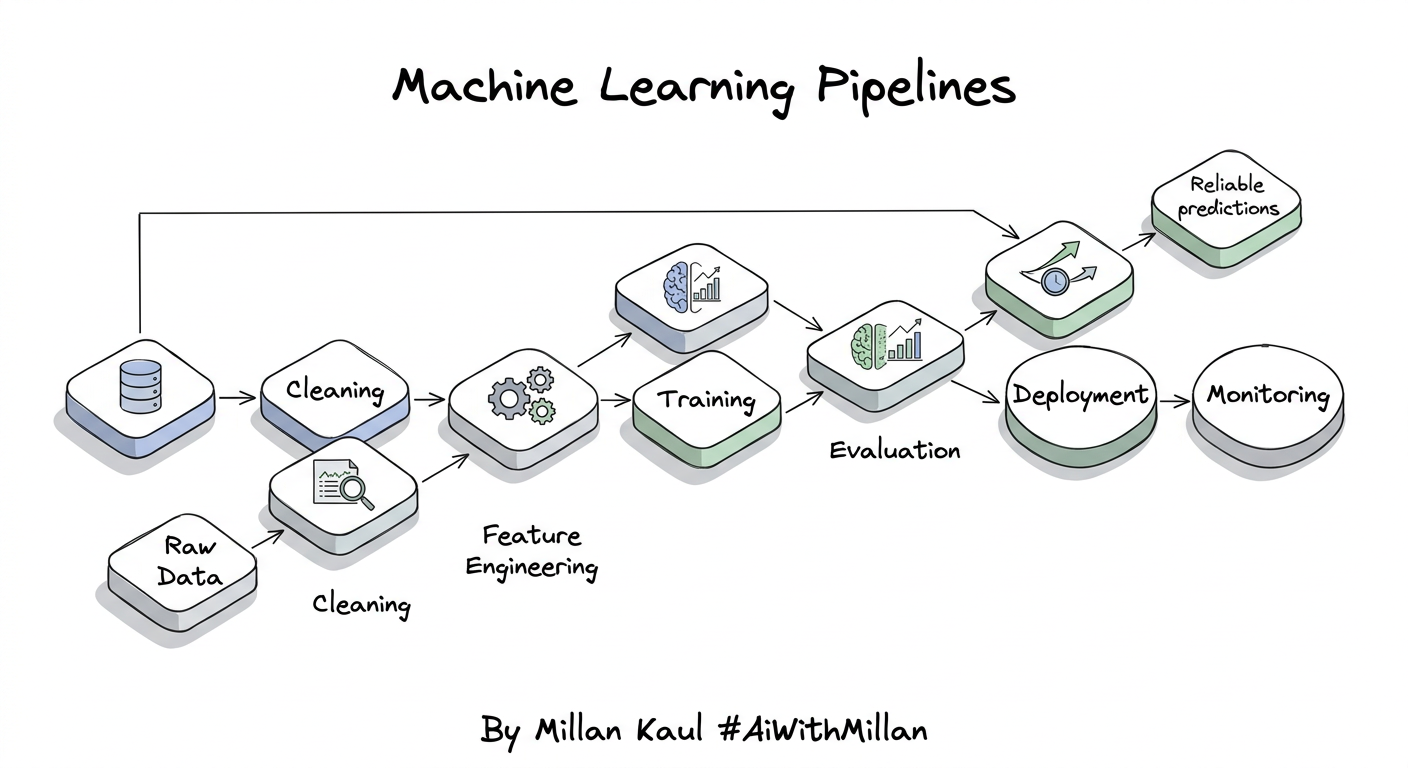
Why ML Pipelines Matter
A data pipeline moves information. An ML pipeline goes further and operationalizes model development.
That matters because ML systems break easily when preprocessing changes between training and inference, when experiments cannot be reproduced, or when models drift after deployment. A pipeline reduces those risks by making each step explicit, testable, and repeatable.
- Automation removes manual glue code.
- Consistency keeps training and inference aligned.
- Scalability supports more models, more data, and more environments.
- Reproducibility makes experiments easier to compare and debug.
Data Collection and Ingestion
This is where data enters the system from databases, APIs, files, logs, or streaming sources.
The goal is not just to collect data, but to bring it into a centralized, reliable format that downstream stages can use without manual cleanup.
Preprocessing and Cleaning
Raw data is rarely model-ready.
This stage handles missing values, duplicates, malformed records, outliers, and noisy entries. It also ensures the same cleaning logic can be reused later during inference.
Feature Engineering
Feature engineering turns raw fields into useful model inputs.
That can include normalization, scaling, categorical encoding, text vectorization, aggregation, or domain-specific transformations. Good features often matter as much as the choice of algorithm.
Model Training
This stage fits a model to the prepared data.
In many workflows, it also includes hyperparameter tuning, cross-validation, and experiment tracking so teams can compare versions and understand what changed.
Evaluation and Validation
A model is not ready just because it trains successfully.
It must be tested on separate data to measure accuracy, robustness, and generalization. This is where teams catch overfitting, bias, and weak performance before deployment.

Deployment
Once validated, the model is packaged and moved into production.
Deployment can mean a real-time API, a batch scoring job, or an embedded service inside a larger system. The key is that the model now produces predictions for users or applications.
Monitoring and Maintenance
Deployment is not the finish line.
Models degrade as data changes, behavior shifts, and real-world conditions evolve. Monitoring checks for data drift, performance degradation, and pipeline failures, then triggers retraining or alerts when needed.
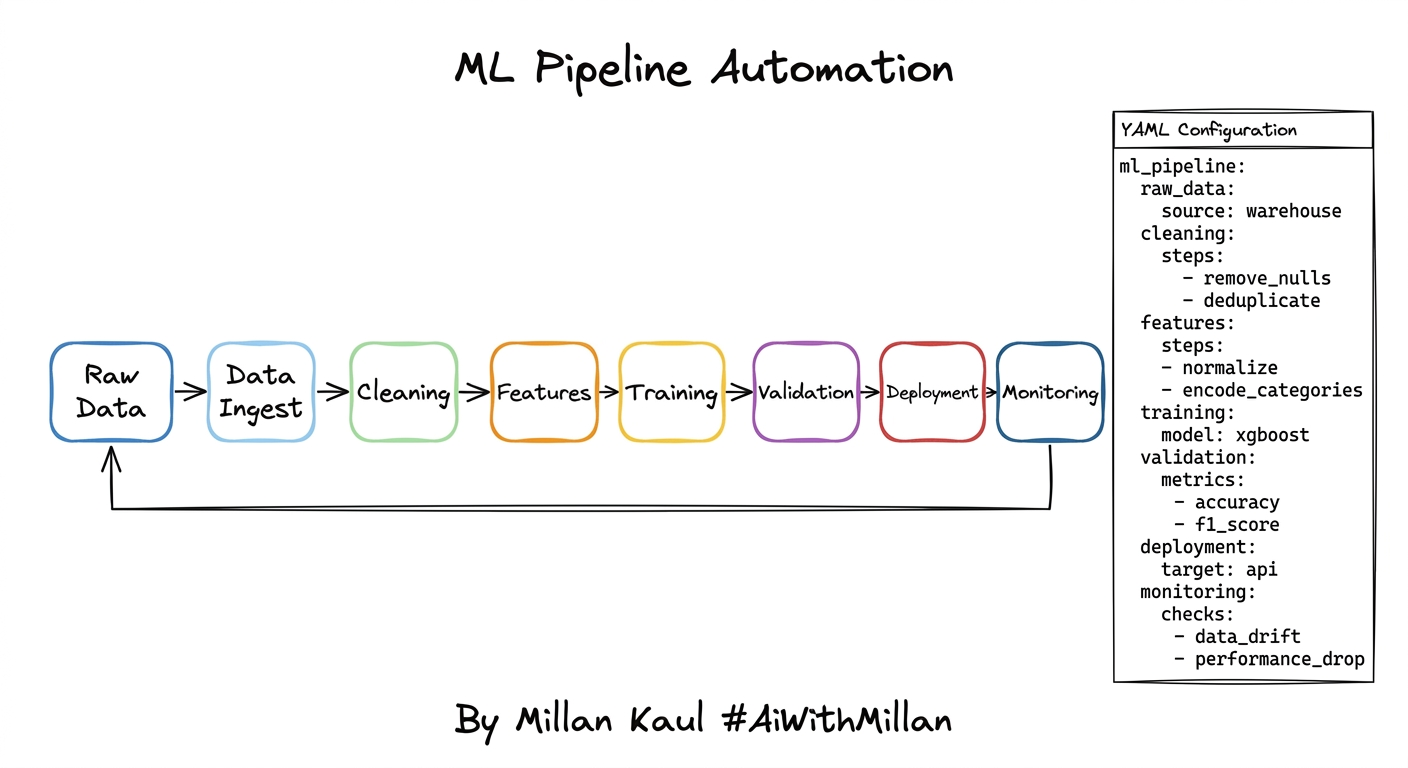
Sample ML Flow
Raw data -> Cleaning -> Features -> Training -> Validation -> Deployment -> Monitoring
Code
Sample ml_pipeline_flow.yaml would look something like this
# File: ml_pipeline_flow.yaml
ml_pipeline:
raw_data:
source: warehouse
cleaning:
steps:
- remove_nulls
- deduplicate
features:
steps:
- normalize
- encode_categories
training:
model: xgboost
validation:
metrics:
- accuracy
- f1_score
deployment:
target: api
monitoring:
checks:
- data_drift
- performance_drop
A simple customer-churn pipeline might pull usage data, clean missing values, encode customer segments, train a classifier, validate it against holdout data, deploy it to score active users, and monitor whether predictions start drifting over time.
Common Tools
Different teams use different tooling depending on scale and complexity.
- Scikit-learn for simple in-memory pipelines in Python.
- Apache Airflow for orchestration and scheduling.
- Google Vertex AI, Azure Machine Learning, and AWS Step Functions for managed cloud pipelines.
What Good Looks Like
A strong ML pipeline is modular, versioned, observable, and repeatable.
- Modular means each step has a clear job.
- Versioned means data, code, and models are tracked.
- Observable means teams can see failures and performance changes.
- Repeatable means the same inputs produce comparable outputs.
ML Pipeline Checklist
- Ingest data from trusted sources.
- Clean and validate inputs before training.
- Reuse preprocessing for inference.
- Track experiments and model versions.
- Validate on separate test data.
- Deploy with a clear rollout strategy.
- Monitor drift and performance continuously.
Machine learning pipelines are the backbone of reliable AI systems. They take ML out of the notebook and turn it into something teams can run, trust, and improve over time.
A good model is important. A good pipeline is what makes that model dependable.