LLM Pre-training: Learning From Trillions of Words
Written by - Millan Kaul
What is Pre-training in LLMs?
Pre-training equips LLMs with broad language knowledge from vast datasets before task-specific tuning.
WHY?
For Developers and SDETs
- Pre-training is how LLMs learn patterns, grammar, and world knowledge from internet-scale data, giving them the “smarts” to handle diverse test prompts without task-specific training.
- Understanding pre-training helps you know what the model “knows” by default (syntax, facts, code patterns) vs what it needs to learn later (your domain rules, policies).
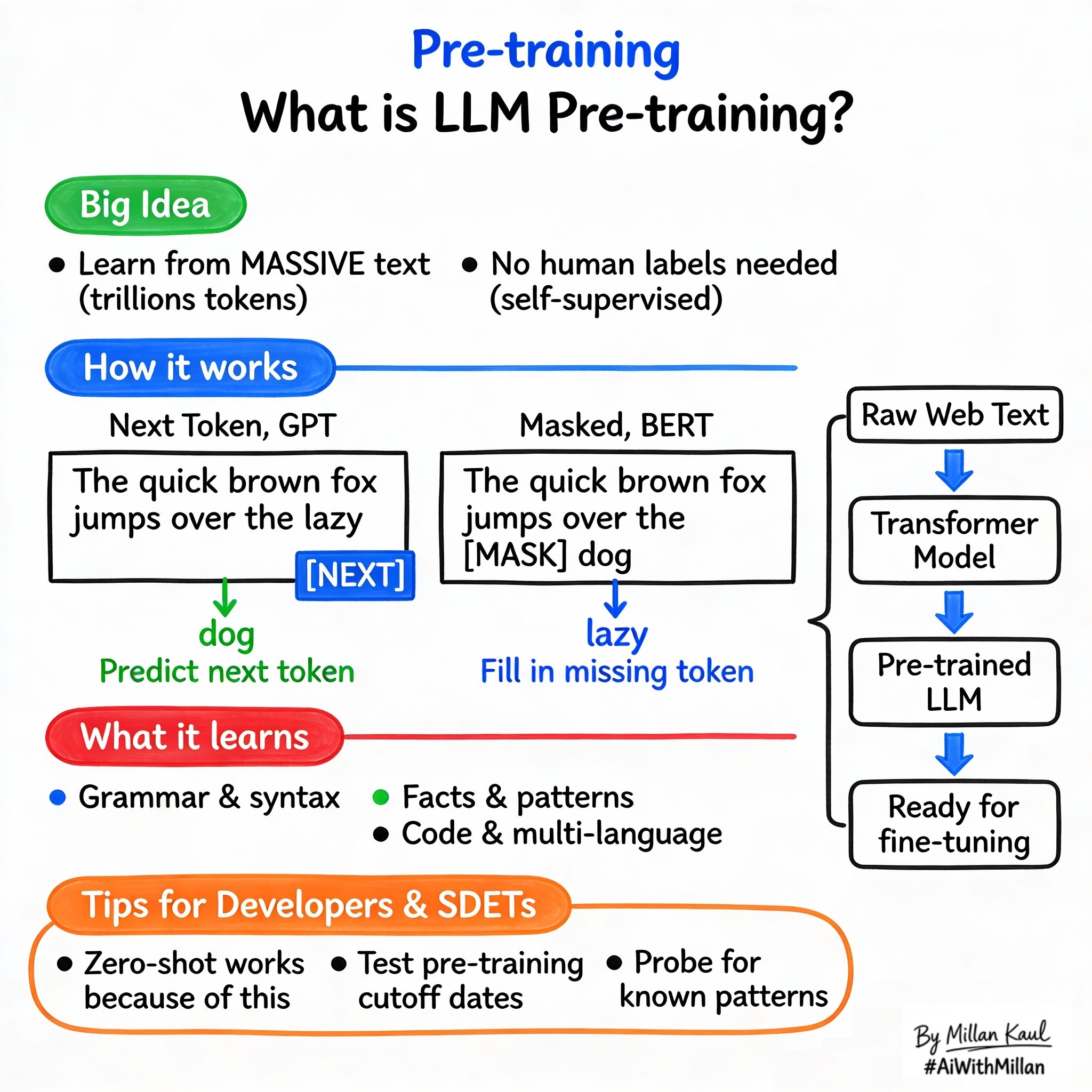
WHAT?
- Pre-training is the initial training phase where a transformer model learns general language understanding by predicting parts of massive unlabeled text datasets (books, web, code).
- Next-token prediction (autoregressive, GPT-style): model sees text so far and predicts the next word/token repeatedly.
- Masked language modeling (bidirectional, BERT-style): randomly hide 15% of tokens and predict them using full context from both sides.
Take these concrete examples:
- Next-token: “The cat sat on the” → predict “mat”.
- Masked: “The [MASK] sat on the mat” → predict “cat”.
- Trained on trillions of tokens from diverse sources like Common Crawl, books, Wikipedia, code repos.
WHEN AND WHERE?
When pre-training knowledge is key
- When using zero/few-shot prompting: the model’s pre-training knowledge is what enables it to follow instructions or reason without examples.
- When debugging unexpected knowledge: model recalls facts, code patterns, or behaviors it “learned” during pre-training.
When you can keep it high-level
- Daily prompt engineering doesn’t require pre-training details; just know it’s the “general smarts” before specialization.
Think about where pre-training impacts your work.
- Model selection docs: “Pre-trained on X trillion tokens, cutoff YYYY-MM” tells you the scope of built-in knowledge.
- Zero-shot capabilities: ability to summarize, translate, code-review without fine-tuning comes from pre-training.
Concrete examples:
- GPT-4 pre-trained to April 2023 knows events up to then but not later (hence hallucinations on fresh data).
- Code models pre-trained on GitHub repos generate syntax and patterns without task training.
- Multilingual models handle 50+ languages because pre-training included diverse web text.
HOW?
1. Conceptual steps
- Massive data preparation
- Clean/filter trillions of tokens from web crawls, books, code (remove duplicates, toxic content).
- Self-supervised objectives
- Next-token: shift input/output by 1, predict forward (decoder-only).
- Masked: hide random tokens, predict using bidirectional context (encoder).
- Train transformer at scale
- Stack 100s of layers, train on 1000s of GPUs for weeks/months, optimizing next-token or masked loss.
- Checkpoint and evaluate
- Save weights when perplexity plateaus; test on benchmarks like GLUE, MMLU.
2. Examples
- Next-token training: “The quick brown fox jumps over the lazy” → predict “dog” (learns grammar, facts).
- Masked training: “The [MASK] [MASK] over the lazy dog” → predict “quick brown fox jumps” (learns bidirectional context).
- Outcome: model learns syntax (“noun verb”), semantics (“animal action”), facts (“Paris=France”).
3. Testing mindset
- Knowledge probes: ask about pre-training-era facts; gaps show cutoff or weak coverage.
- Pattern tests: does it complete common code snippets or sentences correctly?
For Leaders
- Pre-training is the expensive foundation that makes LLMs versatile; it explains why even “zero-shot” prompts work reasonably well out-of-the-box.
- Leaders care because pre-training costs drive model pricing, and its quality sets the ceiling for what fine-tuning or prompting can achieve.
- When selecting base models—pre-training quality affects generalization, safety baselines, and how much fine-tuning you’ll need.
- Focus on outcomes (context length, knowledge cutoff) rather than training recipes.
- In cost models—pre-training is done once by providers; you pay via API costs scaled by model size.
- Benchmark zero-shot performance on your domain docs to gauge if pre-training suffices or fine-tuning is needed.
- Pre-training uses self-supervision (no human labels needed), making it scalable but compute-intensive (weeks/months on thousands of GPUs).
Reference
- “What is LLM training?” IBM
- “LLM Pre-Training and Custom LLMs” Databricks