Why AI Agents Need a Test Harness
Written by - Millan Kaul
Here is Why AI Agents Need a Test Harness:
AI agents are not just models. They are models plus the system around them. That system is the harness.
In plain English, the harness is everything that helps the agent work safely, consistently, and in a way you can test.
Why harness matters
Take this example and think of it like a 5-year-old with LEGO :
The AI model is one LEGO piece, but it cannot become a working robot by itself. It needs the other LEGO parts around it to hold everything together and make it move the right way. That “everything around it” is the harness.
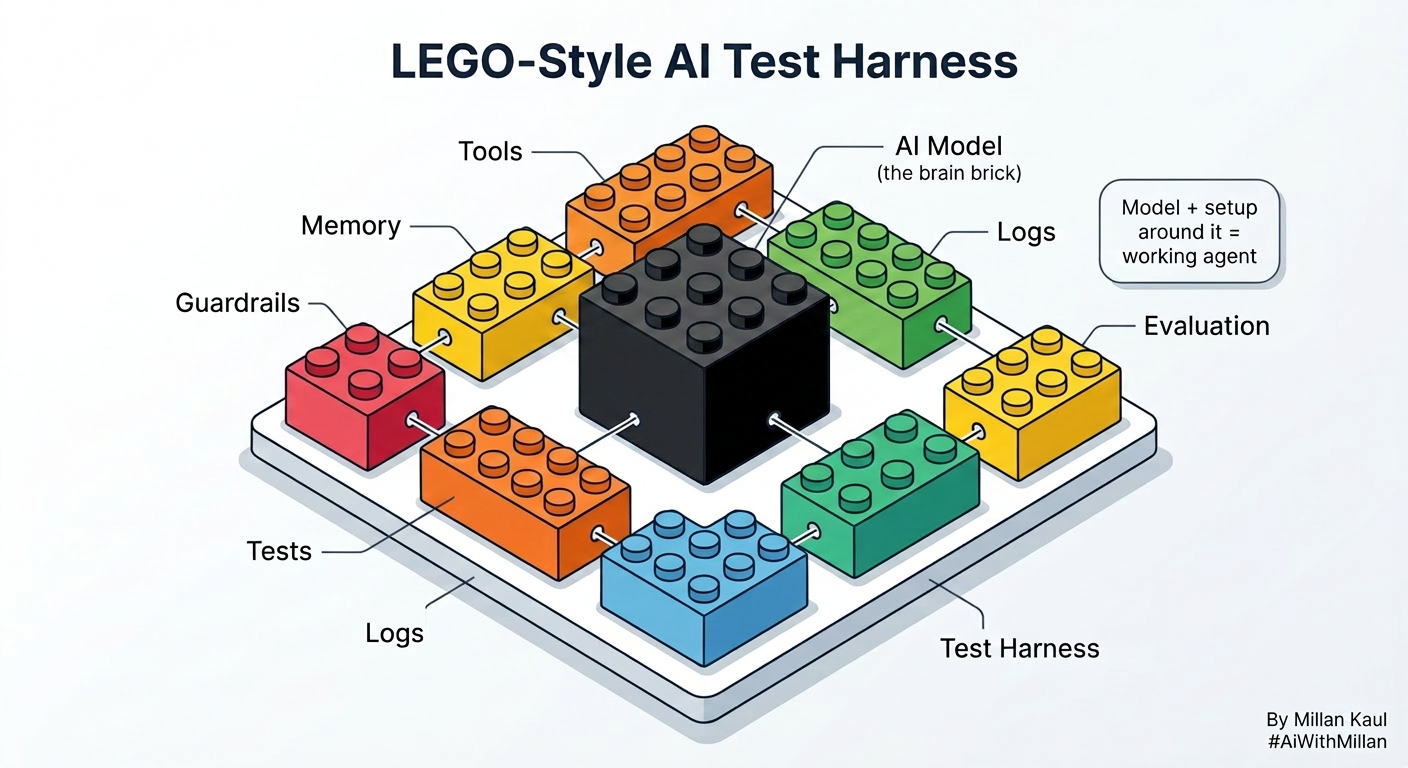
A model can look great in a demo and still fail in production. The moment you add tools, memory, retrieval, permissions, retries, and multiple steps, the real product is no longer just the model. It is the harness around it.
That is why agent reliability becomes a new engineering problem. The harness decides what the agent can do, what it cannot do, how it recovers, and how failures are detected.
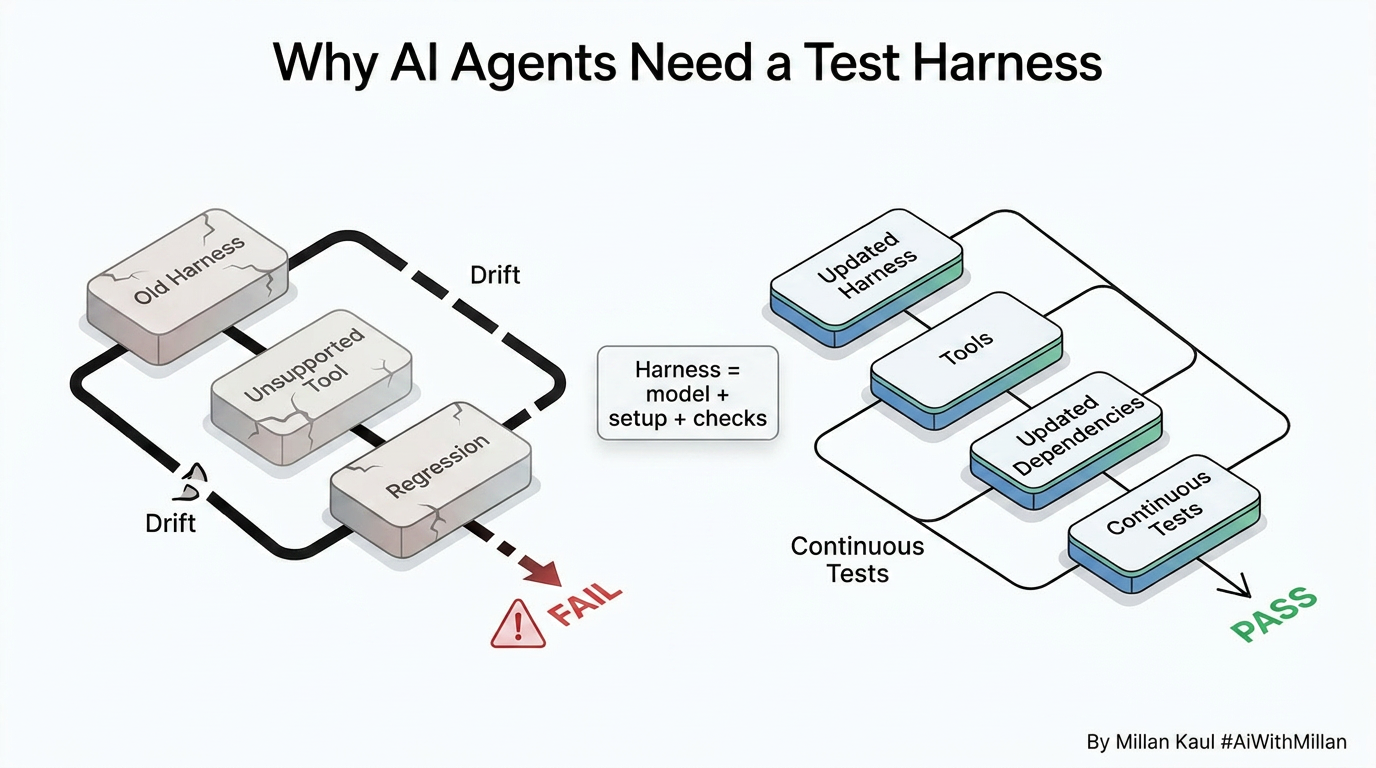
When the old setup breaks
This problem shows up fast when a model starts simple and then grows into a real agent. The early setup may work fine with one prompt, one tool, and one flow. But as soon as the product adds more tools, longer sessions, and customer-specific support paths, the original harness becomes stale.
At that point, the team is no longer only improving the model. They are also rebuilding the environment around it. That is where speed becomes the challenge: new agent versions arrive faster than the old harness can keep up.
What a test harness does
A simple test harness does not need to be fancy.
It just needs to run the agent in a controlled way and verify a few things every time: what tool was called, what came back, and whether the result stayed within cost or policy limits.
A test harness gives you a controlled way to run the agent, observe behavior, and compare results against expected outcomes. It includes fixtures, inputs, outputs, assertions, and logging. In simple terms, it lets you ask: did the agent do the right thing, for the right reason, in the right setup?
# agent.py
def run_agent(user_input: str):
if "order" in user_input.lower():
return {
"tool_called": "get_order_status",
"output": "The status of order #123 is shipped.",
"cost": 0.02,
}
return {
"tool_called": None,
"output": "I could not process the request.",
"cost": 0.01,
}
Harness
# test_harness.py
import yaml
from agent import run_agent
def run_test_case(test_file: str):
with open(test_file, "r") as f:
case = yaml.safe_load(f)
result = run_agent(case["input"])
checks = [
("tool_called", result["tool_called"] == case["expected_tool"]),
("expected_contains", case["expected_contains"].lower() in result["output"].lower()),
("max_cost", result["cost"] <= case["max_cost"]),
]
for name, passed in checks:
if not passed:
raise AssertionError(f"Failed check: {name}")
print(f"PASS: {case['name']}")
if __name__ == "__main__":
run_test_case("tests/order_status.yaml")
This is a small example, but the pattern scales. The same harness can keep validating officially supported agent setups for customers, while a second set of test cases can be used to try newer model and tool combinations without breaking trust in the older ones.
Another example if you are using YAML Test case
# tests/order_status.yaml
name: order status tool routing
input: "What is the status of order #123?"
expected_tool: get_order_status
expected_contains: "order #123"
max_cost: 0.10
For QA teams, this matters because it turns agent behavior into something you can test continuously. You can keep checking supported models and agents for current customers, while also preparing the harness for new versions that are coming next.
Continuous testing solves the drift
The best harnesses are not static, they evolve..
Run the agent on real tasks, observe where it fails, classify the failure, then update the harness and repeat. That loop is the heart of harness engineering.
This is where automation becomes essential:
- regression tests keep supported models stable,
- validation checks catch broken tool calls,
- logs and traces help explain failures,
- and new test paths can be added for incoming model versions.
That means one testing system can support both sides:
- the officially supported models and agents customers rely on today.
- the new and upcoming ones the team is preparing for tomorrow.
A simple setup
A practical harness can look like this:
- test fixtures for common prompts and tasks.
- mocked tools and API responses.
- assertions for success, safety, and format.
- trace logging for every tool call.
- a regression suite for supported models.
- a separate compatibility suite for experimental models.
That setup helps QA, developers, and architects test agent behavior without guessing. It also makes it easier to ship safely when the model changes faster than the product.
Final thought
AI agents do not become reliable because the model is bigger. They become reliable because the harness is testable, observable, and continuously improved. That is why QA is not a side function here. It is the center of the agent strategy.