What is an LLM - Large Language Model ?
Written by - Millan Kaul
How LLMs act as a smart copilot for tests, data, and analysis, while leaders track productivity, risk, and quality.
WHY?
- For testers: LLMs generate test ideas, craft data, and summarize logs in minutes, making testing faster and smarter.
- For leaders: LLMs improve release speed and reduce defects, but require oversight for risks like hallucinations.

WHAT?
- A Large Language Model (LLM) is a very big neural network trained on large text and code datasets to predict the next token (piece of text), which lets it write, summarize, explain, and reason in natural language. en.wikipedia
- “Large” = billions or trillions of parameters; “language model” = it learns patterns in how words and symbols appear together, not facts in a database. en.wikipedia
- Modern LLMs use a smart system called transformers, like a filter that focuses on important words, making them great at handling long texts.
Take these Concrete examples:
- ChatGPT, Claude, and Gemini acting as test idea generators or log explainers. cookbook.openai
-
Open‑source LLMs running locally, which you can point at synthetic data or sanitized logs to experiment safely. nvidia
- From a Leadership view: AI copilots in IDEs that help teams write and refactor code faster, changing how you measure productivity and quality. imd
When and Where?
Good times to use an LLM
- When you need lots of variants: generating boundary cases, negative tests, or localized test data for different regions and user types. Example: Using LLM to generate 10 edge cases for a login API in seconds.
- When you are drowning in unstructured data: long logs, traces, large JSONs, or multiple bug reports that need clustering or summarization.
- For leaders: When you want to run AI pre‑mortems: “If this model went wrong, how could it fail?”, LLMs help simulate risky prompts and misuse scenarios before go‑live.
Times to be careful or avoid
- If the task has a clear, exact rule (schema validation, checksum, price calculation), traditional code is safer and easier to assert.
- For leaders: When incorrect outputs would be high‑impact (compliance notices, financial decisions, medical guidance), use LLMs only with strong guardrails, human review, and precise checks.
- If you cannot safely send data outside your org and don’t have a compliant private deployment, restrict LLM use to synthetic or heavily masked data.
Where in the AI lifecycle?
- In the data and prompt phase: using LLMs to explore datasets, understand biases, and design prompts plus counter‑prompts for red‑teaming (“try to bypass the policy,” “try to exfiltrate secrets”).
- In evals and measurement: LLMs help generate candidate test cases, but you measure them with eval suites (accuracy, robustness, safety) and compare models/versions over time. Example: Using LLM to brainstorm harmful prompts for red-teaming an AI chatbot. From a Leadership angle – In governance workflows: approval checklists for AI features, dashboards showing precision/recall of AI answers, and “AI incident” logs similar to security incidents.
-
In red‑teaming loops: dedicated sessions where testers attack the model-prompt injection, jailbreak attempts, harmful content-and log these as structured “AI defects” with reproduction prompts.
- These goals feed directly into the next section: practical steps for applying LLMs safely in testing.
HOW?
High level, no code-focused on guardrails, precision, and feedback.
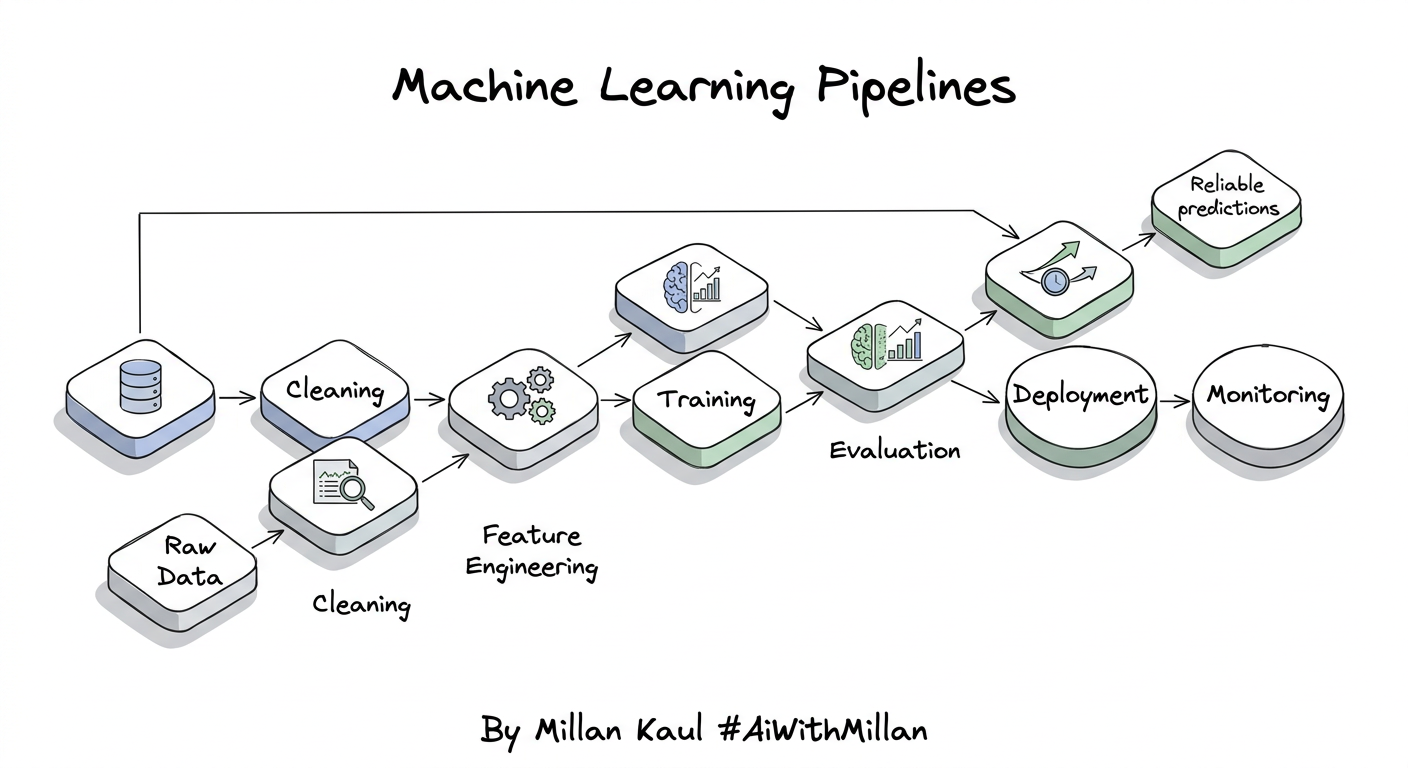
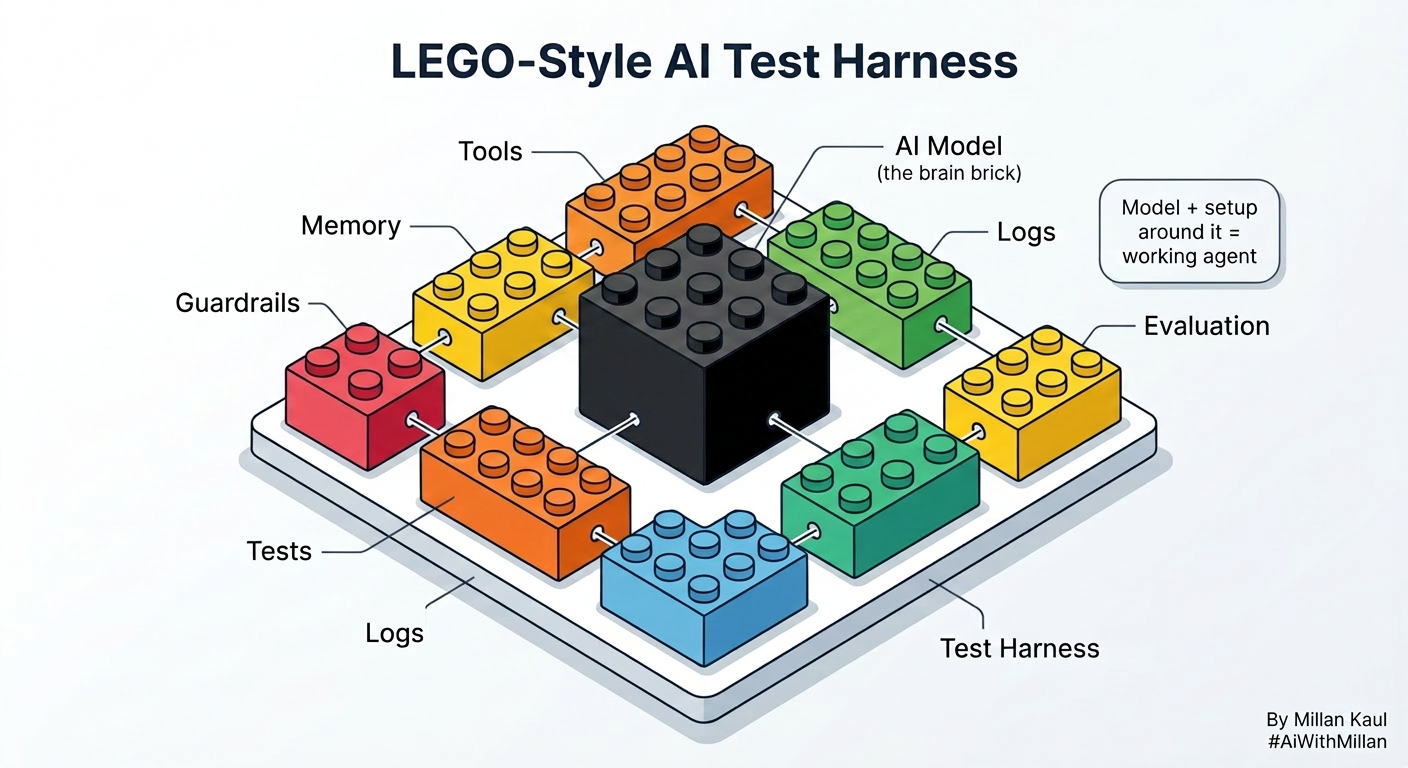
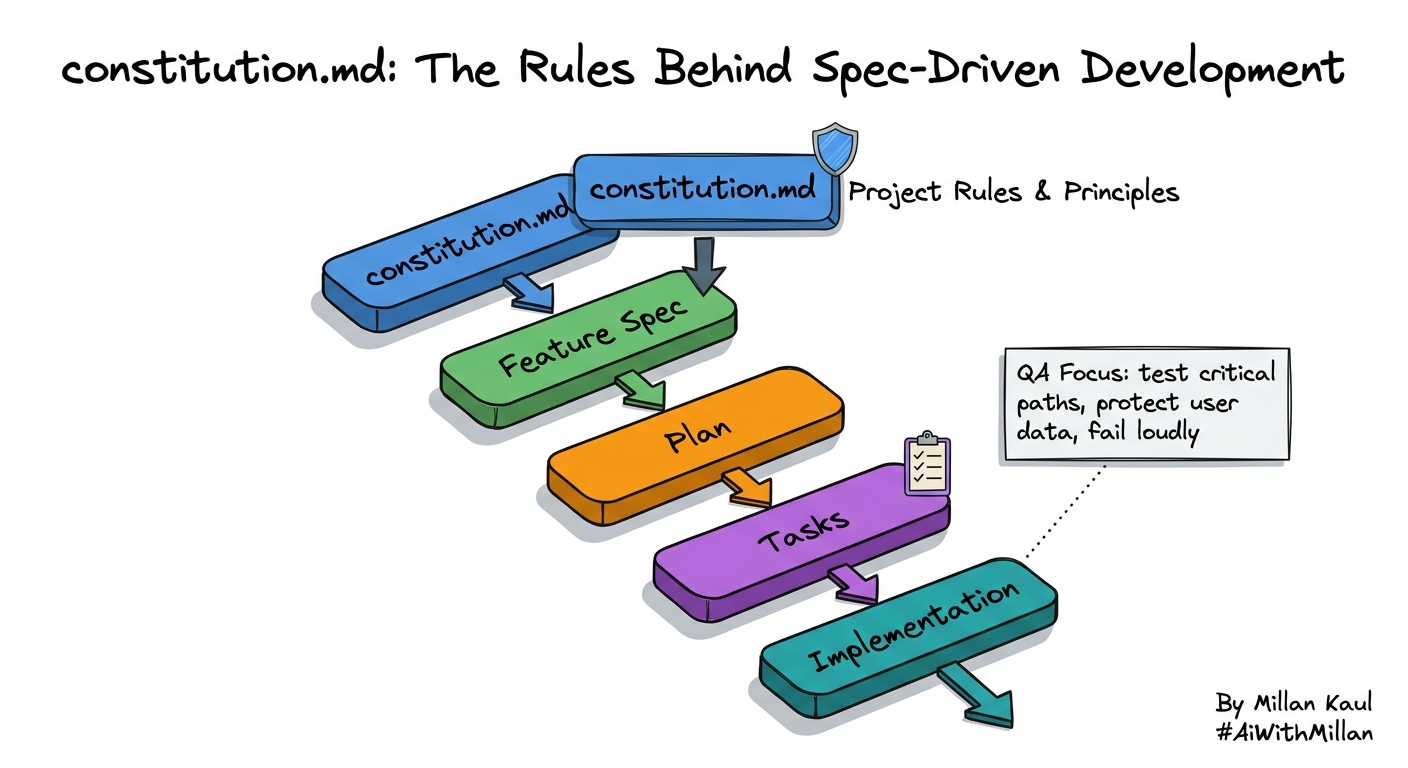
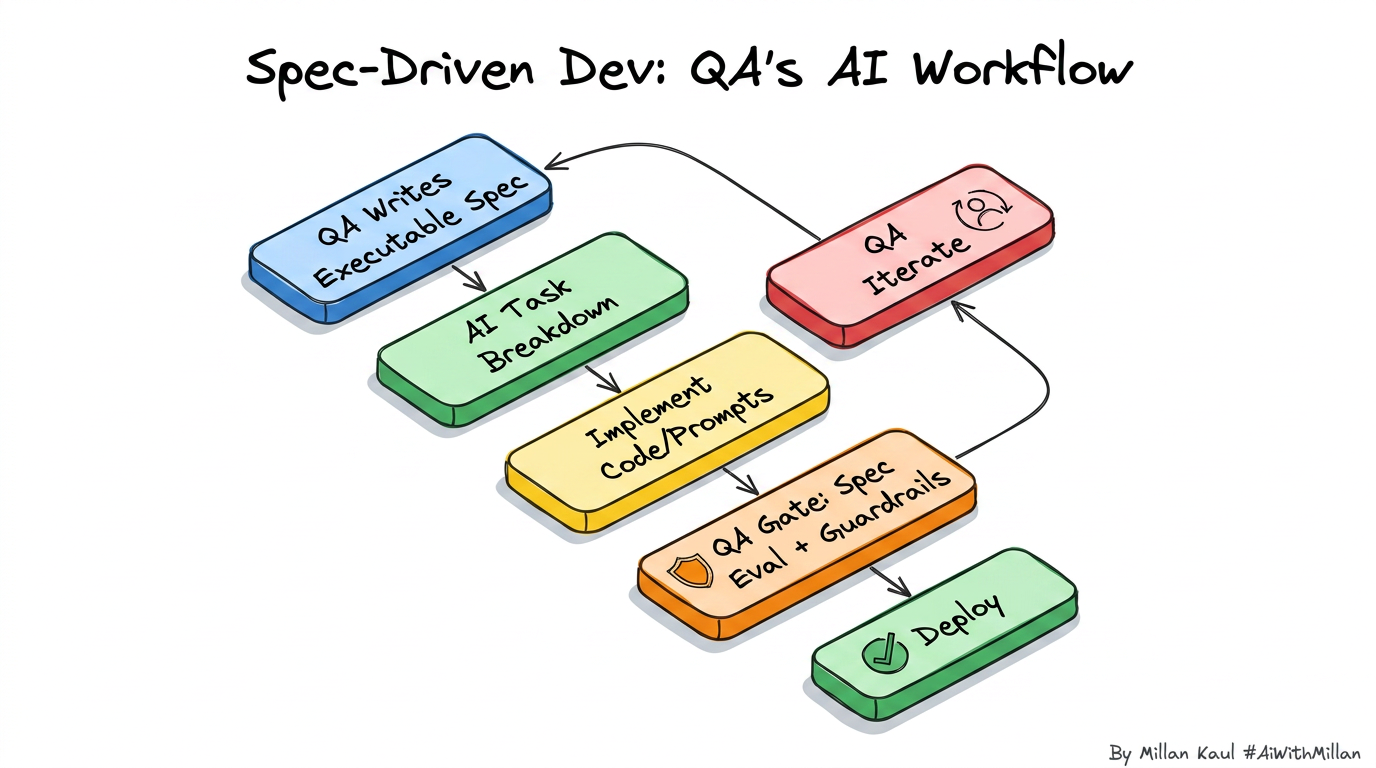
Quick visual (flow)
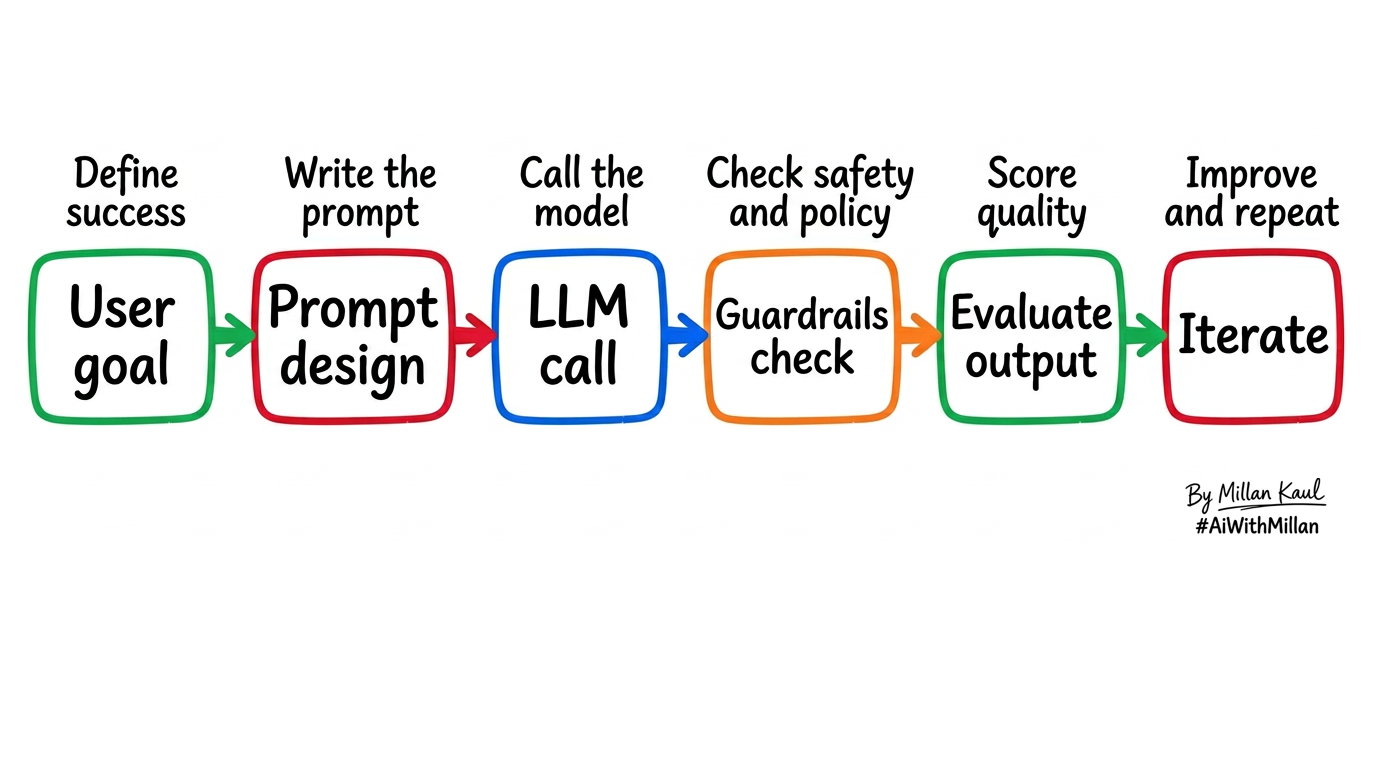
1. Conceptual steps
- Define the AI behavior you want
- e.g., “Summarize error logs into 3 bullet RCA candidates,” or “Generate 10 negative test ideas for this API spec.” cookbook.openai
- Choose the model and deployment
- Decide between public API, VPC/enterprise offering, or self‑hosted model based on data sensitivity, latency, and cost. oracle
- Design prompts and guardrails
- Add clear instructions, examples, and “do not” rules; define output format so you can test it (JSON, table, bullet points).
- Approve policies: no PII in prompts, logging rules, allowed domains, and escalation when the model is unsure. oracle
- Feed data carefully
- Control what context you send (sanitized logs, synthetic customer data) and track which datasets feed which prompts to avoid data leakage. oracle
- Measure and red‑team
- Build small eval sets: prompts + expected patterns, then measure precision/recall, harmful output rate, and hallucination rate.
- Run pre‑mortems: “If this AI fails badly, what does it look like? How do we detect and stop it?” and capture actions in your risk register.
2. Examples
- Log Summarizer with Guardrails
- LLM summarizes error logs but must never invent stack traces. Guardrail: instruct “If you are unsure, say ‘need more data’,” and test with noisy examples to ensure it refuses instead of hallucinating. cookbook.openai
- Negative Test Idea Generator
- LLM reads an API contract and generates invalid inputs and abuse cases; you then select, refine, and add them to your automated suite. Red‑team prompts try to push the model into generating unsafe or irrelevant tests, making sure it still stays on-spec. cookbook.openai
- AI Feature Pre‑mortem
- Before shipping a customer‑facing AI assistant, the team runs a workshop: list “ways this model can hurt users or the business,” use an LLM to brainstorm more, then turn these into evals and policies (blocked topics, escalation to humans).
Leader takeaway: LLMs boost testing efficiency but require oversight to manage risks.
- AWS – “What is LLM? – Large Language Models Explained” aws.amazon
- “Attention Is All You Need” – Vaswani et al., 2017 en.wikipedia
- Wikipedia – “Large language model” en.wikipedia